Java Magazine Example
Hi, this is the example accompanying the article I wrote for Java Magazine. Following this tutorial, you build your custom RAG application using the Rag4j application. First, you set up your environment; you create the application to index all the talks from the JFall 2024 conference. Next, you create a retriever to search for similar content to a question. Finally, you make the answer generator and measure the quality of your solution.
Setting up your environment
You have some choices to work with this example:
- Check out the rag4j project and add your code as a separate class to the project. Rag4j project
- Check out the sample application with all the code. You need to build rag4j on your local machine or have a GitHub account and use the public repo exposed by GitHub to build the project with Maven. Java Magazine Example
Using the maven repository on Github
The project uses maven to manage dependencies and for the build. You need to add Github as a repository. You can use the next settings.xml as an example.
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<activeProfiles>
<activeProfile>github</activeProfile>
</activeProfiles>
<profiles>
<profile>
<id>github</id>
<repositories>
<repository>
<id>central</id>
<url>https://repo1.maven.org/maven2</url>
</repository>
<repository>
<id>github</id>
<url>https://maven.pkg.github.com/rag4j/*</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</profile>
</profiles>
<servers>
<server>
<id>github</id>
<username>YOUR_GITHUB_HANDLE</username>
<password>YOUR_ACCESS_KEY</password>
</server>
</servers>
</settings>
Installing Ollama
Ollama is a tool that runs Large Language Models on your machine. First, navigate to the homepage of Ollama. Download the version for your operating system and install it. Next, open the command prompt and pull the model for the example llama3.2.
ollama pull llama3.2
Creating the Java Application
Time to create the application. Start by creating a java application. I prefer Maven to get the dependencies and build the project. Next step is to create a Java class that can run the application. The following code is a simple example of how to create a Java class that can run the application.
Ingest data
The first step is to create a content store and ingest data. The following code shows how to ingest data into the content store. You need the file with the data, an embedder and a splitter.
String fileName = "jfall/sessions-one.jsonl";
ContentReader contentReader = new JfallContentReader(fileName);
Embedder embedder = new OllamaEmbedder(ollamaAccess);
Splitter splitter = new SentenceSplitter();
InternalContentStore contentStore = new InternalContentStore(embedder);
IndexingService indexingService = new IndexingService(this.contentStore);
indexingService.indexDocuments(contentReader, splitter);
You also need the class to read the content from the file, the JfallContentReader class. The following code shows how to read the content from the file.
package org.rag4j.jm;
import org.rag4j.indexing.ContentReader;
import org.rag4j.indexing.InputDocument;
import org.rag4j.util.resource.JsonlReader;
import java.util.HashMap;
import java.util.List;
import java.util.stream.Stream;
public class JfallContentReader implements ContentReader {
private final String fileName;
public JfallContentReader(String fileName) {
this.fileName = fileName;
}
@Override
public Stream<InputDocument> read() {
Stream.Builder<InputDocument> builder = Stream.builder();
JsonlReader jsonlReader = getJsonlReader();
jsonlReader.getLines().forEach(talk -> {
InputDocument.InputDocumentBuilder documentBuilder = InputDocument.builder()
.documentId(talk.get("title").toLowerCase().replace(" ", "-"))
.text(talk.get("description"))
.properties(new HashMap<>(talk));
builder.add(documentBuilder.build());
});
return builder.build();
}
private JsonlReader getJsonlReader() {
List<String> properties = List.of(
"speakers",
"title",
"description",
"room",
"time",
"tags"
);
return new JsonlReader(properties, this.fileName);
}
}
The result of the previous code is a ContentStore with the chunks of text from the talks. The next step is to create a retriever to search for similar content to a question. If you follow the available repository, you can run step one. Read the comments, change the splitter to see he results change.
Create a retriever
The InternalContentStore is also a retriever. You can use the findRelevantChunks method to search for similar content to the question. The following code shows how to search for similar content.
List<RelevantChunk> relevantChunks = contentStore.findRelevantChunks(question, maxResults);
for (RelevantChunk relevantChunk : relevantChunks) {
LOGGER.info("Document id: {}", relevantChunk.getDocumentId());
LOGGER.info("Chunk id: {}", relevantChunk.getChunkId());
LOGGER.info("Text: {}", relevantChunk.getText());
LOGGER.info("Score: {}", relevantChunk.getScore());
logSeparator();
}
You have now reached step two in the sample repository.
Respond with an answer using the ChatService
Getting an answer requires a few classes with different responsibilities:
- The ChatService is the class that you use to get an answer to a question. There is a specific ChatService for Ollama, and one for OpenAI. The ChatService is the wrapper around the LLM.
- The AnswerGenerator is the class that generates the answer, making use of the ChatService.
- The RetrievalStrategy is the class that retrieves the relevant chunks from the content store and creates a context from them. Multiple strategies are available, like TopNRetrievalStrategy and WindowRetrievalStrategy.
OllamaAccess ollamaAccess = new OllamaAccess();
ChatService chatService = new OllamaChatService(ollamaAccess);
AnswerGenerator answerGenerator = new AnswerGenerator(chatService);
RetrievalStrategy retrievalStrategy = new TopNRetrievalStrategy(contentStore);
RetrievalOutput retrievalOutput = this.retrievalStrategy.retrieve(question, maxResults);
String answer = answerGenerator.generateAnswer(question, retrievalOutput.constructContext());
LOGGER.info("Question: {}", question);
LOGGER.info("Answer: {}", answer);
This is step three in the sample repository.
Quality measurement
The final step is the measure the quality of your solution. The quality of a RAG solution consists of three parts the diagram below shows the different parts of the quality measurement.
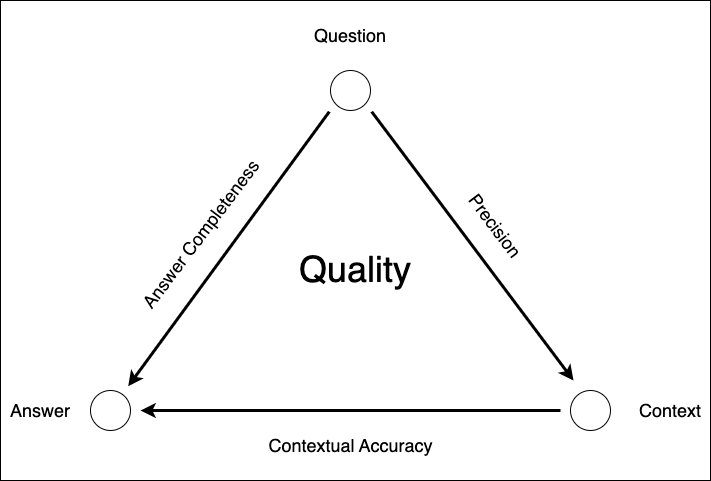
The quality component is responsible for determining the quality of the generated text and the retrieved chunks, all related to the question from the user. There are three metrics to determine the overall quality of your RAG:
- The precision: the quality of the results of the retriever in relationship to the question.
- Contextual Accuracy: the quality of the answer in relationship to the context.
- Answer Completeness: the quality of the answer in relationship to the question.
Precision ~ quality of the retriever
You do not have a judgement list, but an LLM can assist you in generating one. From each chunk, you generate a question using an LLM. Next, the questions go through the retriever; they should return the chunk from which the question was generated. The precision is a score between 0 and 1, where one is perfect.
In the next code block, you see how to create the judgement list, and how to calculate the precision. Note the ObservedRetriever. This is a wrapper around a retriever that collects data to calculate the precision.
QuestionGenerator questionGenerator = new QuestionGenerator(chatService);
QuestionGeneratorService questionGeneratorService =
new QuestionGeneratorService(contentStore, questionGenerator);
Path savedFilePath = questionGeneratorService.generateQuestionAnswerPairsAndSaveToTempFile(fileName);
LOGGER.info("Saved file: {}", savedFilePath);
ObservedRetriever observedRetriever = new ObservedRetriever(contentStore);
RetrievalQualityService retrievalQualityService = new RetrievalQualityService(observedRetriever);
List<QuestionAnswerRecord> questionAnswerRecords =
retrievalQualityService.readQuestionAnswersFromFilePath(savedFilePath, false);
RetrievalQuality retrievalQuality =
retrievalQualityService.obtainRetrievalQuality(questionAnswerRecords, embedder);
LOGGER.info("Correct: {}", retrievalQuality.getCorrect());
LOGGER.info("Incorrect: {}", retrievalQuality.getIncorrect());
LOGGER.info("Quality using precision: {}", retrievalQuality.getPrecision());
LOGGER.info("Total questions: {}", retrievalQuality.totalItems());
Contextual Accuracy
The context is constructed from the chunks retrieved by the retriever. The generator generates the answer. The answer should be deduced from the context. The contextual accuracy is between 1 and 5, where five is perfect. This score is obtained through the LLM by asking the LLM about the quality of the answer concerning the context.
Similar to the ObservedRetriever, the framework comes with an ObservedAnswerGenerator. This class is a wrapper around the answer generator that collects data to calculate the contextual accuracy. The RAGObserverPersistor is an interface that you can implement to store the data. The next code block shows how to calculate the contextual accuracy. It uses the LoggingRAGObserverPersistor to log the observed data.
ObservedAnswerGenerator answerGenerator = new ObservedAnswerGenerator(chatService);
retrieveAnswer(answerGenerator, question, maxResults);
RAGObserver observer = RAGTracker.getRAGObserver();
RAGTracker.cleanup();
RAGObserverPersistor persistor = new LoggingRAGObserverPersistor();
persistor.persist(observer);
AnswerQualityService answerQuality = new AnswerQualityService(chatService);
AnswerQuality quality = answerQuality.determineQualityOfAnswer(observer);
LOGGER.info("Quality of answer coming from the context: {}, Reason {}}",
quality.getAnswerFromContextQuality().getQuality(), quality.getAnswerFromContextQuality().getReason());
Answer Completeness
The generator generates the answer. The answer should answer all aspects of the question. The answer accuracy is a score between 1 and 5, where five is perfect. The score is obtained through the LLM by asking the LLM about the quality of the answer concerning the question.
The next code block shows how to calculate the answer completeness. It can be added to the previous code block to calculate the overall quality of the answer.
LOGGER.info("Quality of answer compared to the question: {}, Reason: {}}",
quality.getAnswerToQuestionQuality().getQuality(), quality.getAnswerToQuestionQuality().getReason());
Change the strategy to a DocumentRetrievalStrategy to retrieve the whole document instead of a chunk. Watch the difference in results
Conclusion
This example shows how to create a simple RAG application. The quality of the RAG solution is determined by the precision, the contextual accuracy, and the answer completeness. The precision is the quality of the retriever in relationship to the question. The contextual accuracy is the quality of the answer in relationship to the context. The answer completeness is the quality of the answer in relationship to the question. The quality of the RAG solution is determined by these three metrics.
Want to try this yourself? Checkout the GitHUb project: Java Magazine Example
Output
If you do not want to try this yourself, you can check the output of the code in the next code block
/opt/homebrew/Cellar/openjdk@21/21.0.5/libexec/openjdk.jdk/Contents/Home/bin/java -javaagent:/Users/jettrocoenradie/Applications/IntelliJ IDEA Ultimate.app/Contents/lib/idea_rt.jar=54716:/Users/jettrocoenradie/Applications/IntelliJ IDEA Ultimate.app/Contents/bin -Dfile.encoding=UTF-8 -Dsun.stdout.encoding=UTF-8 -Dsun.stderr.encoding=UTF-8 -classpath /Users/jettrocoenradie/Development/personal/rag4j-java-magazine/target/classes:/Users/jettrocoenradie/.m2/repository/org/rag4j/rag4j/1.5.0/rag4j-1.5.0.jar:/Users/jettrocoenradie/.m2/repository/org/apache/opennlp/opennlp-tools/2.5.0/opennlp-tools-2.5.0.jar:/Users/jettrocoenradie/.m2/repository/org/apache/commons/commons-math3/3.6.1/commons-math3-3.6.1.jar:/Users/jettrocoenradie/.m2/repository/org/slf4j/slf4j-api/2.0.7/slf4j-api-2.0.7.jar:/Users/jettrocoenradie/.m2/repository/org/slf4j/slf4j-simple/2.0.7/slf4j-simple-2.0.7.jar:/Users/jettrocoenradie/.m2/repository/org/json/json/20240303/json-20240303.jar:/Users/jettrocoenradie/.m2/repository/org/apache/commons/commons-csv/1.12.0/commons-csv-1.12.0.jar:/Users/jettrocoenradie/.m2/repository/commons-io/commons-io/2.17.0/commons-io-2.17.0.jar:/Users/jettrocoenradie/.m2/repository/commons-codec/commons-codec/1.17.1/commons-codec-1.17.1.jar:/Users/jettrocoenradie/.m2/repository/ai/djl/api/0.30.0/api-0.30.0.jar:/Users/jettrocoenradie/.m2/repository/com/google/code/gson/gson/2.11.0/gson-2.11.0.jar:/Users/jettrocoenradie/.m2/repository/com/google/errorprone/error_prone_annotations/2.27.0/error_prone_annotations-2.27.0.jar:/Users/jettrocoenradie/.m2/repository/net/java/dev/jna/jna/5.14.0/jna-5.14.0.jar:/Users/jettrocoenradie/.m2/repository/org/apache/commons/commons-compress/1.27.1/commons-compress-1.27.1.jar:/Users/jettrocoenradie/.m2/repository/com/knuddels/jtokkit/1.1.0/jtokkit-1.1.0.jar org.rag4j.jm.AppRAG
[main] INFO org.rag4j.jm.AppRAG - Document id: build-the-best-knowledge-retriever-for-your-large-language-model.
[main] INFO org.rag4j.jm.AppRAG - Chunk id: 4
[main] INFO org.rag4j.jm.AppRAG - Text: An essential part of RAG is the retrieval part.
[main] INFO org.rag4j.jm.AppRAG - Score: 15.23797700427602
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.jm.AppRAG - Document id: build-the-best-knowledge-retriever-for-your-large-language-model.
[main] INFO org.rag4j.jm.AppRAG - Chunk id: 3
[main] INFO org.rag4j.jm.AppRAG - Text: To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose.
[main] INFO org.rag4j.jm.AppRAG - Score: 19.02969381348981
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.jm.AppRAG - Document id: build-the-best-knowledge-retriever-for-your-large-language-model.
[main] INFO org.rag4j.jm.AppRAG - Chunk id: 4
[main] INFO org.rag4j.jm.AppRAG - Text: An essential part of RAG is the retrieval part.
[main] INFO org.rag4j.jm.AppRAG - Score: 16.872212193426076
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.jm.AppRAG - Document id: build-the-best-knowledge-retriever-for-your-large-language-model.
[main] INFO org.rag4j.jm.AppRAG - Chunk id: 3
[main] INFO org.rag4j.jm.AppRAG - Text: To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose.
[main] INFO org.rag4j.jm.AppRAG - Score: 18.941479184476453
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.jm.AppRAG - Question: What is RAG?
[main] INFO org.rag4j.jm.AppRAG - Answer: Retrieval Augmented Generation (RAG) is a pattern that aims to overcome the knowledge problem in text generation models by using retrieval mechanisms to retrieve relevant information from a database or knowledge base before generating new text.
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.jm.AppRAG - Question: Who talked about RAG?
[main] INFO org.rag4j.jm.AppRAG - Answer: I couldn't find any information about who specifically talked about RAG in the provided context. The context only mentions that RAG was developed as a solution to overcome the knowledge problem, but it doesn't mention who specifically discussed or proposed this concept.
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is it a common requirement for participants in a hands-on learning experience?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is it possible for a user to utilize a computer system located outside of their usual environment?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: What programming languages are commonly used in a retrieval algorithm optimization workshop?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: How do these strategies help create a more comprehensive understanding of the model's capabilities?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is the primary goal of chunking mechanisms to improve understanding and representation of complex data structures?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Will a conference dedicated to a specific type of research be held?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Will a technology that can create new content be limited by its reliance on existing data?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is it possible for a participant to benefit from prior preparation before attending an event?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Can one set up an open-source large language model directly from their own computer?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Does a Large Language model's understanding of its own limitations ever change?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Are these tools considered ordinary goods due to their widespread availability?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is the retrieval process a crucial component of this organization's activities?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Can a specific method of training artificial intelligence models be employed to resolve the issue of incomplete information in AI systems?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is there an optimal method for evaluating the effectiveness of information search strategies?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is the concept of retrieving information from existing sources a common practice among researchers?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Will a newly integrated retriever improve the performance of an existing Large Language Model?
[main] INFO org.rag4j.rag.generation.QuestionGeneratorService - Generated question: Is this technology based solely on the analysis of user behavior?
[main] INFO org.rag4j.jm.AppRAG - Saved file: /var/folders/50/ds20b4252qjb6_nk6v84t5mh0000gn/T/questionAnswerPairs2650460898584228046/jfall_questions_answers_sample.csv
[main] INFO org.rag4j.jm.AppRAG - Correct: [build-the-best-knowledge-retriever-for-your-large-language-model._9, build-the-best-knowledge-retriever-for-your-large-language-model._12, build-the-best-knowledge-retriever-for-your-large-language-model._10, build-the-best-knowledge-retriever-for-your-large-language-model._16, build-the-best-knowledge-retriever-for-your-large-language-model._15, build-the-best-knowledge-retriever-for-your-large-language-model._14, build-the-best-knowledge-retriever-for-your-large-language-model._2, build-the-best-knowledge-retriever-for-your-large-language-model._1, build-the-best-knowledge-retriever-for-your-large-language-model._4, build-the-best-knowledge-retriever-for-your-large-language-model._8]
[main] INFO org.rag4j.jm.AppRAG - Incorrect: [build-the-best-knowledge-retriever-for-your-large-language-model._13, build-the-best-knowledge-retriever-for-your-large-language-model._11, build-the-best-knowledge-retriever-for-your-large-language-model._0, build-the-best-knowledge-retriever-for-your-large-language-model._3, build-the-best-knowledge-retriever-for-your-large-language-model._6, build-the-best-knowledge-retriever-for-your-large-language-model._5, build-the-best-knowledge-retriever-for-your-large-language-model._7]
[main] INFO org.rag4j.jm.AppRAG - Quality using precision: 0.5882352941176471
[main] INFO org.rag4j.jm.AppRAG - Total questions: 17
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.jm.AppRAG - Question: What is RAG?
[main] INFO org.rag4j.jm.AppRAG - Answer: Retrieval Augmented Generation (RAG) is a pattern that was developed to address the knowledge problem in natural language generation. The purpose of RAG is to retrieve relevant information from an external knowledge source before generating text. This allows models to draw upon existing knowledge and avoid relying solely on their own internal state, thereby improving the accuracy and coherence of generated text.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Question: What is RAG?
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Context: An essential part of RAG is the retrieval part. To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Answer: Retrieval Augmented Generation (RAG) is a pattern that was developed to address the knowledge problem in natural language generation. The purpose of RAG is to retrieve relevant information from an external knowledge source before generating text. This allows models to draw upon existing knowledge and avoid relying solely on their own internal state, thereby improving the accuracy and coherence of generated text.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Relevant chunks:
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._9: It is easy to learn, so you can focus on understanding and building the details of the components during the workshop.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._12: To find the optimum combination, you'll use quality metrics for the retriever as well as the other components of the RAG system.You can do the workshop using Python or Java.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._10: You experiment with different chunking mechanisms (sentence, max tokens, semantic).
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._16: Check out the web page and gear up for a great session!https://rag4j.org/conference/2024/09/27/workshop-jfall-2024.html
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._15: Dive into pre-workshop materials and come ready to make the most of this experience.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._14: You can also run an open-source LLM on Ollama on your local machine.We’ve created a dedicated web page to help you prepare, with all the resources you need at your fingertips.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._2: Large Language models (LLMs) only have the knowledge they acquired through learning, and even that knowledge does not include all the details.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._1: Tools to generate text, images, or data are now common goods.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._4: An essential part of RAG is the retrieval part.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._3: To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._8: Vector search got a jump start with the rise of LLMs and RAG.This workshop aims to build a high-quality retriever, integrate the retriever into your LLM solution and measure the overall quality of your RAG system.The workshop uses our Rag4j/Rag4p framework, which we created especially for workshops.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Window to chunkIds:
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Window texts:
[main] INFO org.rag4j.jm.AppRAG - Quality of answer compared to the question: 4, Reason: The answer is partially correct as it mentions Retrieval Augmented Generation (RAG) but lacks specific details about its implementation or how it addresses the knowledge problem.}
[main] INFO org.rag4j.jm.AppRAG - Quality of answer coming from the context: 4, Reason The answer partially captures the essence of RAG but lacks specificity about the external knowledge source and its role in improving generated text accuracy and coherence. It does not mention the internal state or avoid reliance on it, which are crucial aspects of the RAG mechanism.}
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
[main] INFO org.rag4j.jm.AppRAG - Question: Who talked about RAG?
[main] INFO org.rag4j.jm.AppRAG - Answer: Unfortunately, I couldn't find any information on who specifically talked about RAG in the provided context. The context mentions that RAG is a part of RAG but does not mention anyone discussing or mentioning it. Therefore, I cannot provide an answer to your question.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Question: Who talked about RAG?
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Context: An essential part of RAG is the retrieval part. To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Answer: Unfortunately, I couldn't find any information on who specifically talked about RAG in the provided context. The context mentions that RAG is a part of RAG but does not mention anyone discussing or mentioning it. Therefore, I cannot provide an answer to your question.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Relevant chunks:
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._4: An essential part of RAG is the retrieval part.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._3: To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Window to chunkIds:
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Window texts:
[main] INFO org.rag4j.jm.AppRAG - Quality of answer compared to the question: 4, Reason: The answer provides some information related to RAG, such as being "a part of RAG", which suggests some level of understanding about the term. However, it fails to provide a specific person or entity that talked about RAG, leaving the answer incomplete.}
[main] INFO org.rag4j.jm.AppRAG - Quality of answer coming from the context: 2, Reason The answer is partially correct but does not contain exact information from the context. It mentions "who specifically talked about RAG", which is not present in the provided context.}
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------
Process finished with exit code 0
And part of the output after changing the retrieval strategy to a DocumentRetrievalStrategy
[main] INFO org.rag4j.jm.AppRAG - Question: Who talked about RAG?
[main] INFO org.rag4j.jm.AppRAG - Answer: Jettro Coenradie and Daniël Spee.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Question: Who talked about RAG?
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Context: Generative AI is here to stay. Tools to generate text, images, or data are now common goods. Large Language models (LLMs) only have the knowledge they acquired through learning, and even that knowledge does not include all the details. To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose. An essential part of RAG is the retrieval part. Retrieval is not new. The search or retrieval domain is rich with tools, metrics and research. The new kid on the block is semantic search using vectors. Vector search got a jump start with the rise of LLMs and RAG.This workshop aims to build a high-quality retriever, integrate the retriever into your LLM solution and measure the overall quality of your RAG system.The workshop uses our Rag4j/Rag4p framework, which we created especially for workshops. It is easy to learn, so you can focus on understanding and building the details of the components during the workshop. You experiment with different chunking mechanisms (sentence, max tokens, semantic). After that, you use various strategies to construct the context for the LLM (TopN, Window, Document, Hierarchical). To find the optimum combination, you'll use quality metrics for the retriever as well as the other components of the RAG system.You can do the workshop using Python or Java. We provide access to a remote LLM. You can also run an open-source LLM on Ollama on your local machine.We’ve created a dedicated web page to help you prepare, with all the resources you need at your fingertips. Dive into pre-workshop materials and come ready to make the most of this experience. Check out the web page and gear up for a great session!https://rag4j.org/conference/2024/09/27/workshop-jfall-2024.html
description: Generative AI is here to stay. Tools to generate text, images, or data are now common goods. Large Language models (LLMs) only have the knowledge they acquired through learning, and even that knowledge does not include all the details. To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose. An essential part of RAG is the retrieval part. Retrieval is not new. The search or retrieval domain is rich with tools, metrics and research. The new kid on the block is semantic search using vectors. Vector search got a jump start with the rise of LLMs and RAG.This workshop aims to build a high-quality retriever, integrate the retriever into your LLM solution and measure the overall quality of your RAG system.The workshop uses our Rag4j/Rag4p framework, which we created especially for workshops. It is easy to learn, so you can focus on understanding and building the details of the components during the workshop. You experiment with different chunking mechanisms (sentence, max tokens, semantic). After that, you use various strategies to construct the context for the LLM (TopN, Window, Document, Hierarchical). To find the optimum combination, you'll use quality metrics for the retriever as well as the other components of the RAG system.You can do the workshop using Python or Java. We provide access to a remote LLM. You can also run an open-source LLM on Ollama on your local machine.We’ve created a dedicated web page to help you prepare, with all the resources you need at your fingertips. Dive into pre-workshop materials and come ready to make the most of this experience. Check out the web page and gear up for a great session!https://rag4j.org/conference/2024/09/27/workshop-jfall-2024.html
time: Thu 10:35 am - 12:30 pm
title: Build the best knowledge retriever for your Large Language Model.
room: Hands-on labs
speakers: Jettro Coenradie, Daniël Spee
tags: Hands-on Lab, Big Data & Machine Learning, Intermediate
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Answer: Jettro Coenradie and Daniël Spee.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Relevant chunks:
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._4: An essential part of RAG is the retrieval part.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - build-the-best-knowledge-retriever-for-your-large-language-model._3: To overcome the knowledge problem, the Retrieval Augmented Generation (RAG) pattern arose.
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Window to chunkIds:
[main] INFO org.rag4j.rag.tracker.LoggingRAGObserverPersistor - Window texts:
[main] INFO org.rag4j.jm.AppRAG - Quality of answer compared to the question: 4, Reason: The answer matches the proposed question, mentioning both individuals who worked on RAG, but it doesn't provide a clear connection or context between them. More information would strengthen the answer.}
[main] INFO org.rag4j.jm.AppRAG - Quality of answer coming from the context: 4, Reason The answer partially matches the context as it contains the names of two speakers, but lacks details such as their roles or specific contributions to the workshop. The context does not explicitly mention the names Jettro Coenradie and Daniël Spee in relation to the Retrieval Augmented Generation (RAG) pattern.}
[main] INFO org.rag4j.jm.AppRAG - ---------------------------------------