Yesterday was the first public appearance of my latest project, Rag4p-GUI. This project is a graphical interface for the Rag4p library. The goal for that project is to create a basic library or framework that we can use during workshops. You can understand the complete framework in an hour, essential for our workshops. The problem with the project is that it needed a GUI. So, I always used the command line during presentations, distracting me from the information I wanted to share. Therefore, I started working on a GUI. It could get a bit out of hand. In this post, I want to share the first version of the GUI. I’ll discuss the features that it has right now.
The GUI consists of three parts. The first part is indexing the content into a store. Rag4p provides access to Weaviate, OpenSearch and a custom in-memory database. The second part deals with retrieving the context for the Large Language Model. Again, you can use Weaviate, OpenSearch, or a custom in-memory database. The third part is the generation of the answer. Currently, the Rag4p project provides access to OpenAI, Amazon Bedrock and Ollama for LLMs.
Indexing
The project’s adaptability shines through in its ability to handle different datasets. With three different datasets, often in a small and larger variant, and a reader class for each dataset due to their non-uniform layout, the project ensures flexibility. Another essential component is the splitter, with the project offering three options: the sentence splitter, the max token splitter, and the single chunk splitter. You can test drive the different splitters using the Chunking tab, found after choosing the Indexing tab.
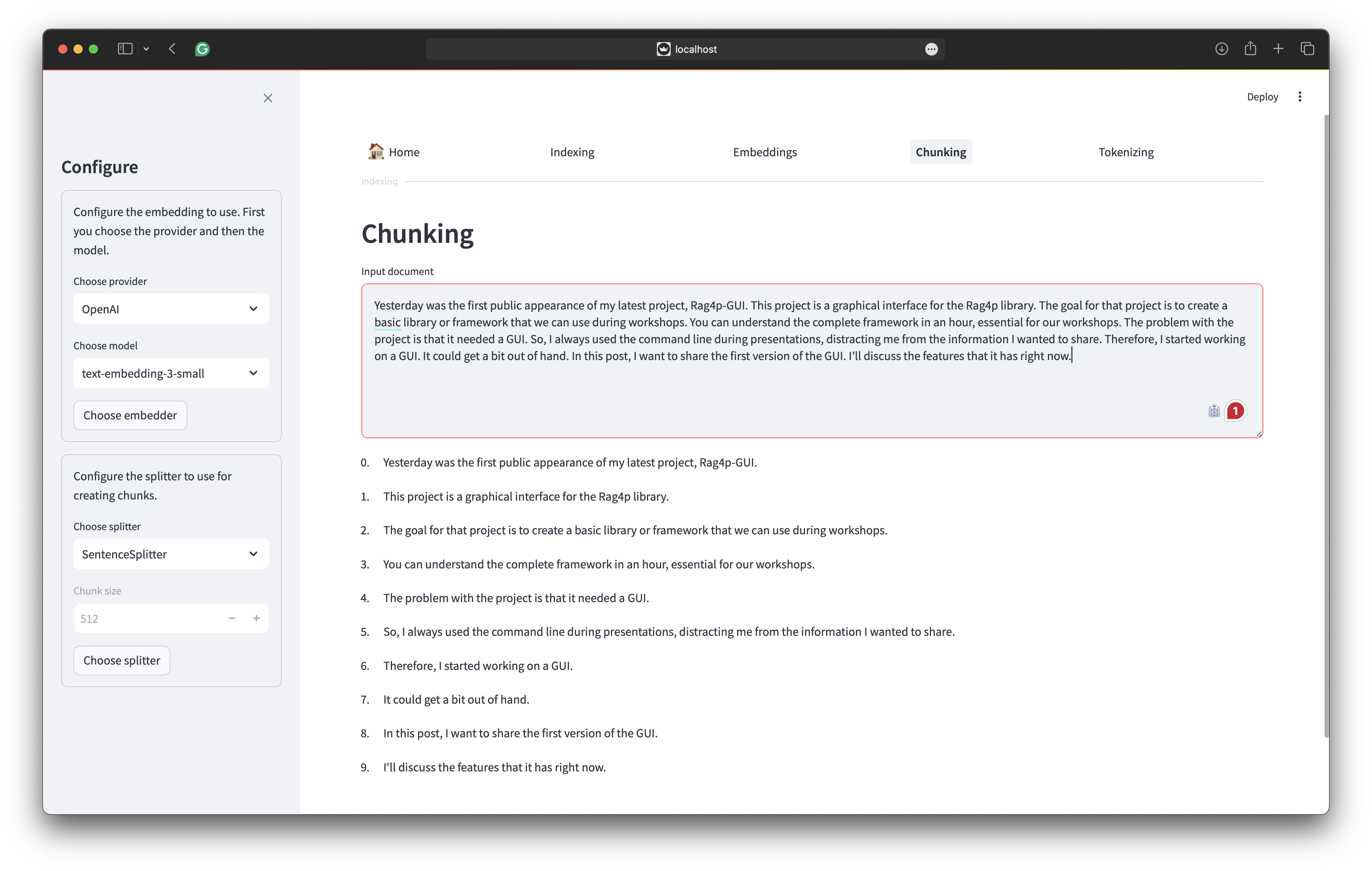
With the proper chunks, it is time to talk about embeddings. When working with semantic search and vectors to capture the semantics of your chunk, you have to choose the right embedder. The Rag4p project offers four embedding providers: OpenAI, Bedrock, Ollama and Onnx. Some providers offer different models. You can select the model you want to use. The Embedding tab allows you to test the different embedders. By selecting one of the backups of the internal data stores, you can visualise the embeddings and enter your query to locate the query embedding next to the embeddings in your store. The following image shows a sample of the screen.
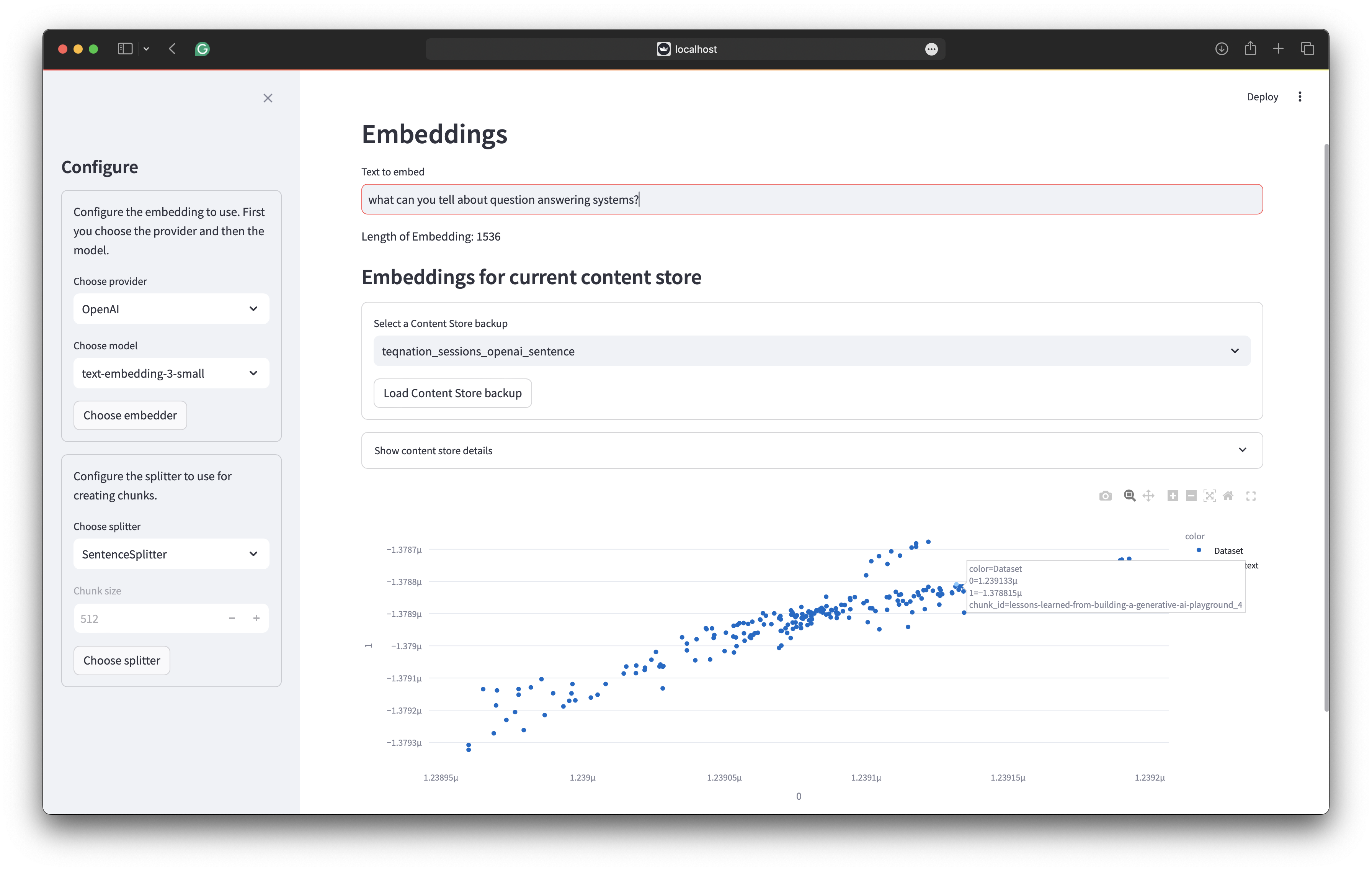
Creating embeddings using services like OpenAI and Bedrock costs money and time. Therefore, the GUI provides an interface to store embeddings in a vector store and back up the in-memory store. You can manage the collections in Weaviate and OpenSearch through the interface. The following table presents an overview of the different collections and how they were realised, including what splitter, embedding, and dataset were used.
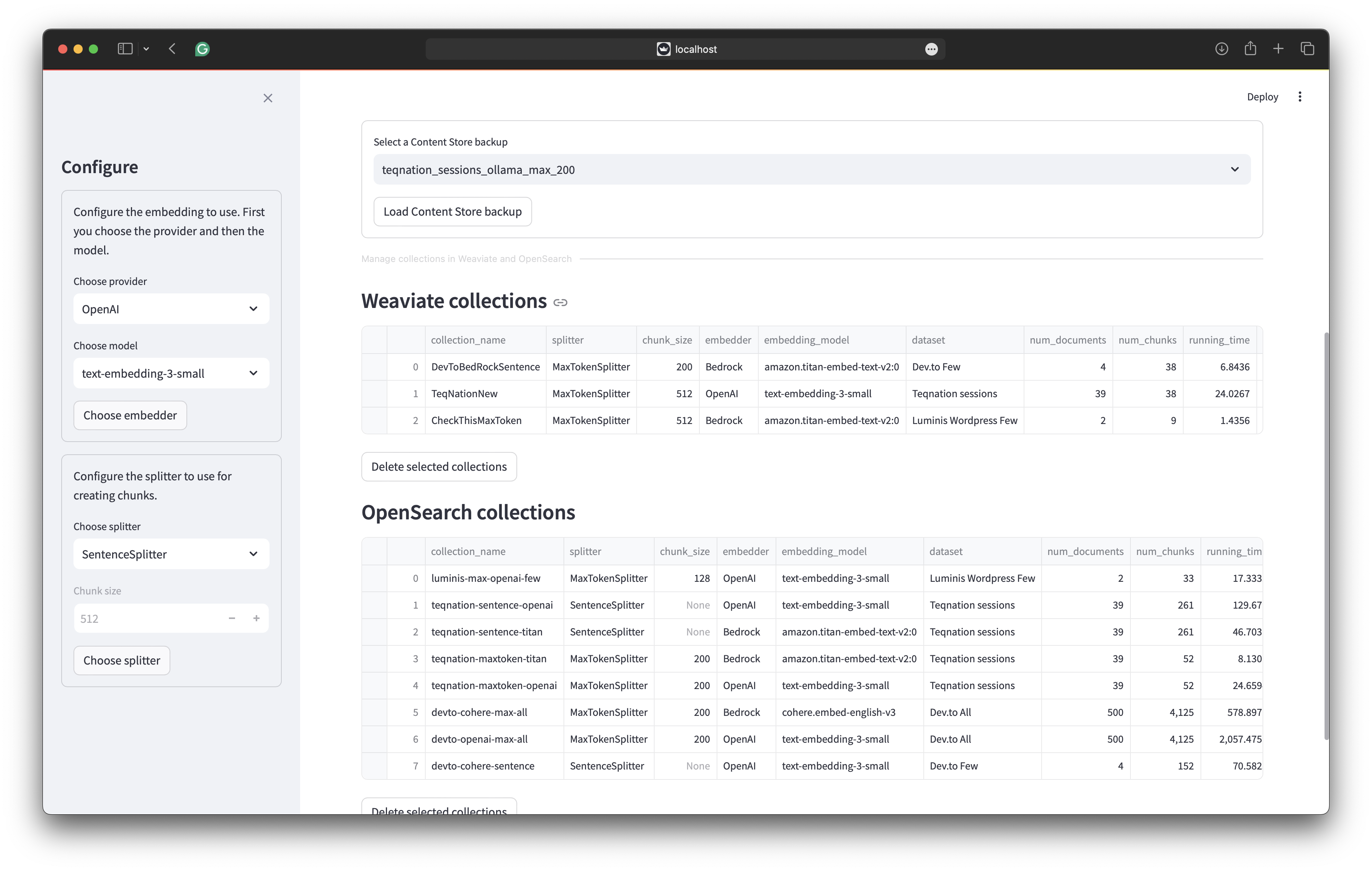
Retrieving
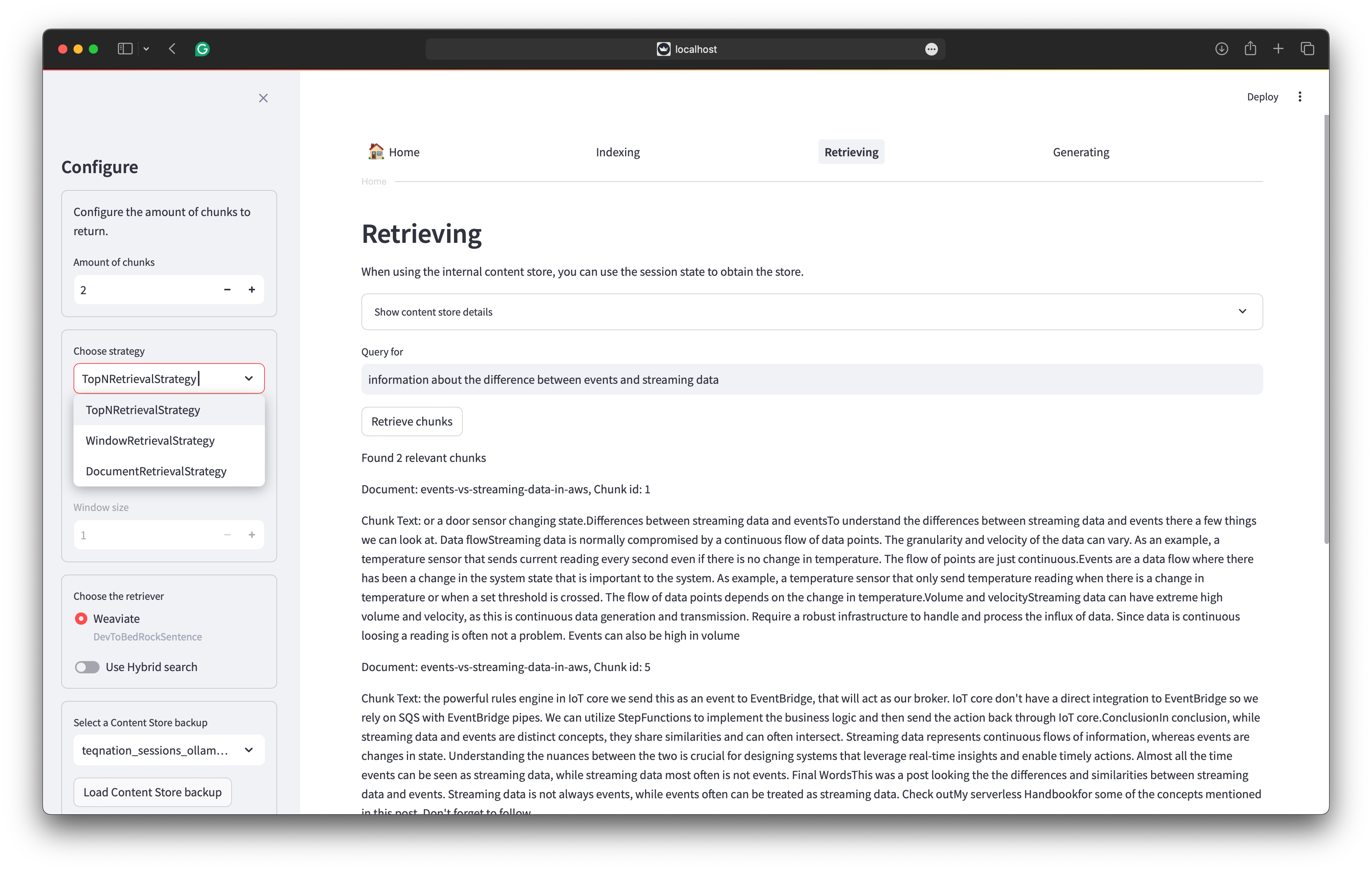
The retrieval part of the GUI is the most straightforward part. You choose the store to use. THe internal store, Weaviate or OpenSearch. For each store you select the collection to use. For Weaviate and OpenSearch you can choose hybrid search. Finally you select the retrieval strategy together with the amount of relevant chunks to retrieve. The following image shows the retrieval screen.
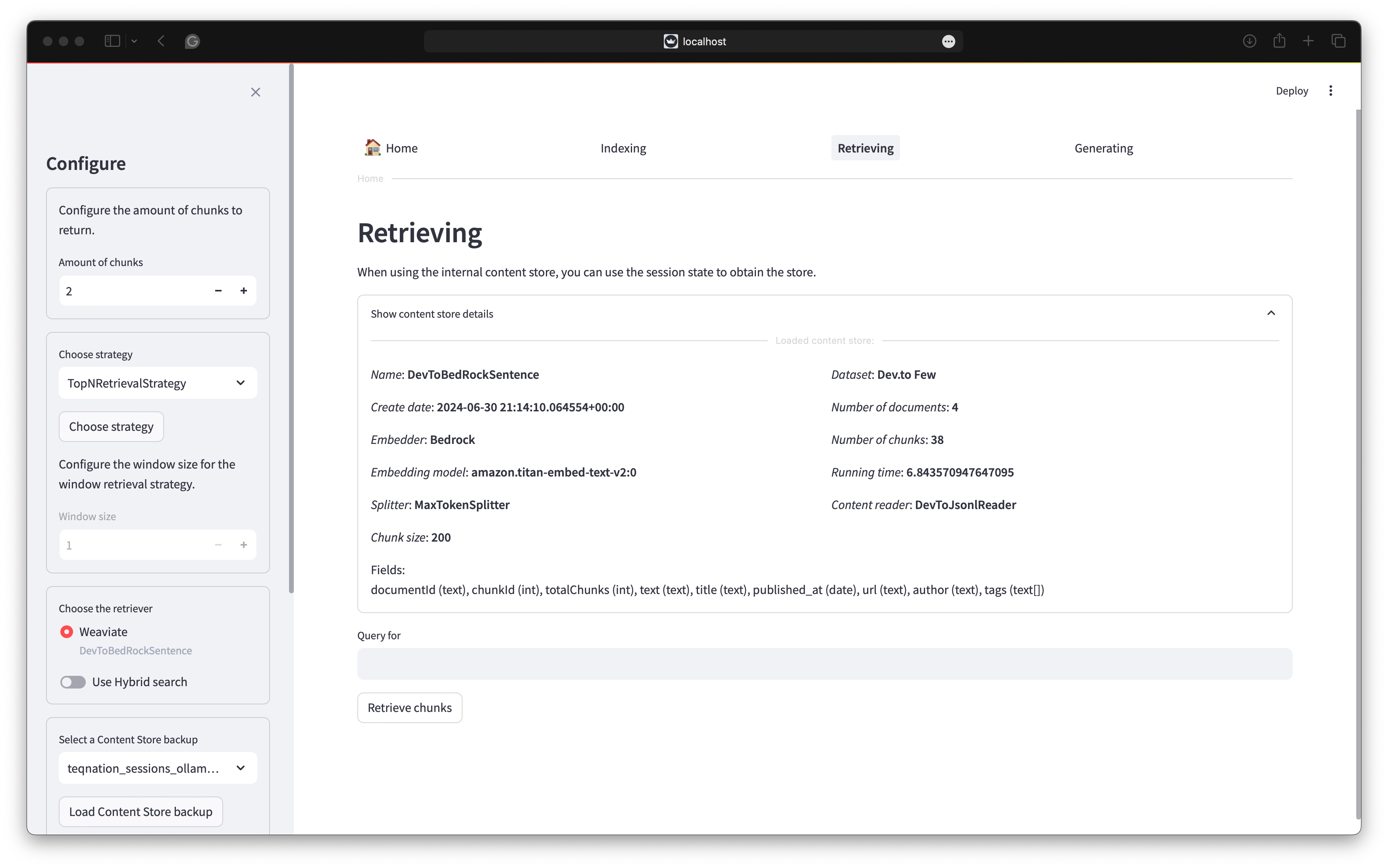
At the moment, Rag4p supports three retrieval strategies. The first strategy is the TopN strategy. This strategy retrieves the top N chunks based on the similarity between the query and the chunks. The second strategy is the Window strategy. This strategy retrieves the top N chunks based on the similarity between the query and the chunks and the chunks before and after the relevant chunk. The third strategy is the document strategy. This strategy retrieves the complete document of the appropriate chunk. The document retrieval includes the metadata of the document. This way, you can return information about the document’s title and author. The following image shows the retrieval screen.
Generating
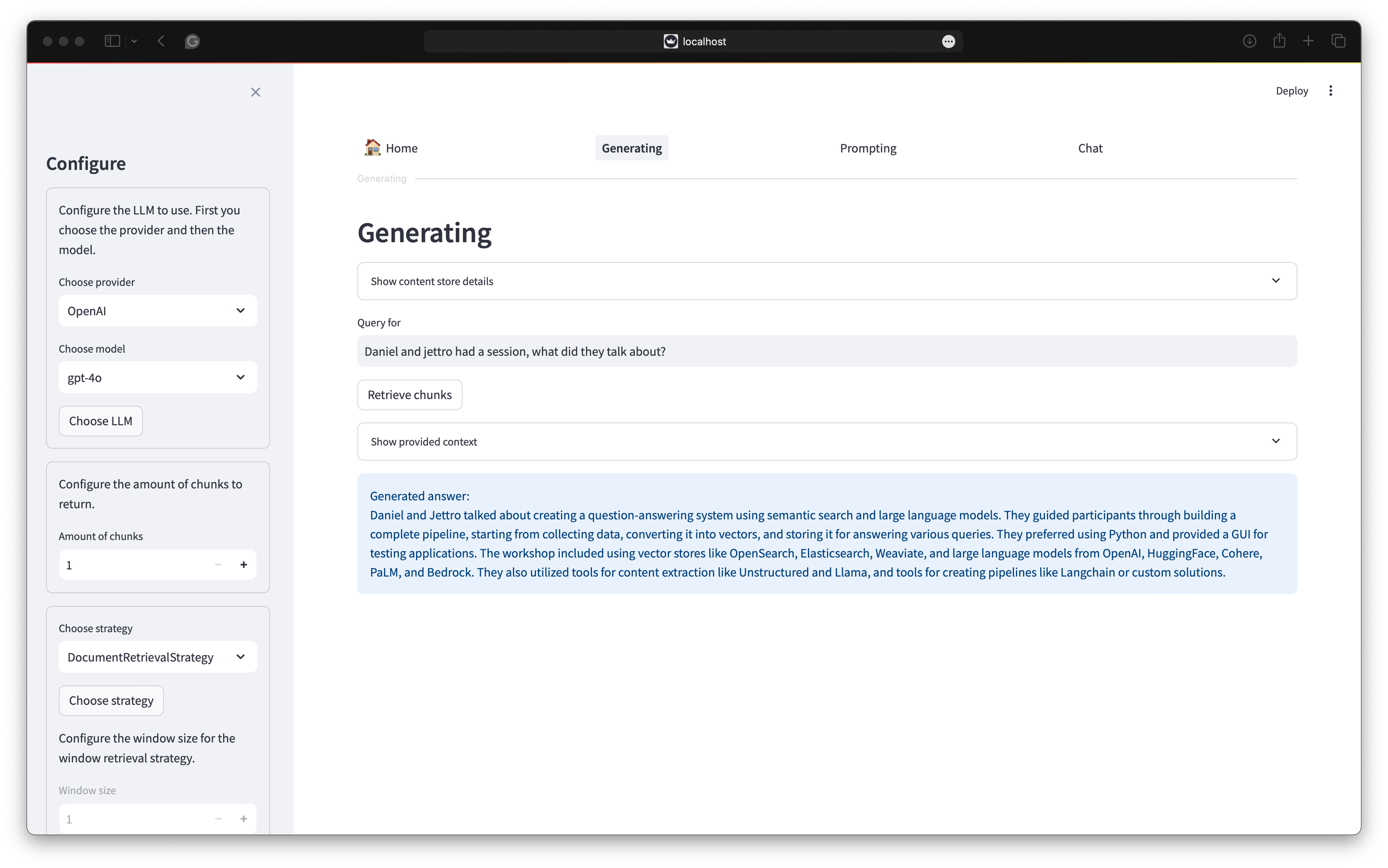
Here we combine everything we have done so far. You select the content store to use with the collection. Select the retrieval strategy and the amount of relevant chunks to retrieve. Finally, you select the generator to use. The generator can be OpenAI, Bedrock or Ollama. The following image shows the generation screen. We used the document retrieval strategy in combination with hybrid search. With hybrid search, the speakers field is also searched. Therefore our talk at TeqNation is found.
The GUI is available on Github. The project is still in its early stages.
]]>
